1. Memory Hierarchy
1) Computer's Memory
- Memory : data 및 프로그램을 저장
- 컴퓨터 메모리의 Design constraints(설계 제약 조건)
- Capacity(용량) : 어느 정도인지?
- 용량이 있다면 application이 이를 사용하도록 개발될 가능성이 높다.
- Cost(per bit) : 얼마나 비싼지?
- practical(실제) 시스템의 경우 메모리 비용은 다른 구성 요소와 관련하여 합리적이어야 한다.
- Access time : 얼마나 빠른지?
- 최고의 성능을 얻으려면 메모리가 프로세서를 따라잡을 수 있어야 한다.
- Capacity(용량) : 어느 정도인지?
- Modern memory technology(현대 메모리 기술)
- 더 작고, 더 비싼(비트 당 더 높은 비용), 더 빠른 메모리
- 더 크고, 더 저렴한(비트 당 비용 절감), 더 느린 메모리
- single memory 구성요소 또는 기술에 의존하지 않고 multiple memory 구성 요소(hierarchy : 계층)을 사용하기 위해
2) Memory Hierarchy
- 더 작고, 더 비싸고, 더 빠른 메모리가 더 크고, 더 저렴하고, 더 느린 메모리로 보완되는 memory component의 organization
- 이 organization의 성공 key는 프로세서를 따라가는 것이다.

- 계층의 lower-level memory에 대한 액세스를 어떻게 최소화할 수 있을까?
- 자주 사용하는 데이터를 계층의 upper-level에서 저장
- Locality of reference(참조의 지역)
- 프로그램은 주어진 시간에 상대적으로 작은 부분주소 공간에 액세스하는 경향이 있음
- 이 부분은 포로그램이 실행됨에 따라 변경됨
- 두 가지 유형의 Locality
- Temporal locality(시간적 지역성)
- item이 참조되면 곧 다시 참조되는 경향이 있음
- ex. 반복 루프
- Spatial locality(공간적 지역성)
- item이 참조되면 주소가 가까운 item이 곧 참조되는 경향이 있음
- ex. 배열, 테이블
- Temporal locality(시간적 지역성)
3) Average Access Time
- HIT : 액세스된 데이터가 상위 레벨에서 발견됨
- H(Hit rate) : 상위 레벨에서 발견된 모든 메모리 액세스의 fraction(비율)
- T1 : 상위 레벨로의 접근 시간
- T2 : 하위 레벨로의 접근 시간
- MISS : 액세스된 데이터가 하위 레벨에서 발견됨
- 프로세서는 다음 레벨에서 데이터가 로드될 때까지 기다린 다음 액세서를 계속함
- M(Miss rate) : 1 - H(Hit rate)
- 예시
- Level 1의 액세스 시간은 0.1μs이다.
- Level 2의 액세스 시간은 1μs이다.
- 메모리 액세스의 95%가 Level 1(H = 0.95)에서 발견된다고 가정하자
- 바이트에 액세스하는 평균 시간은 다음과 같이 표현할 수 있다.
- T = (0.95)(0.1μs) + (0.05)(0.1μs + 1μs) = 0.095 + 0.055 = 0.15μs
→ 상위 레벨로 갔다가 실패하고 하위 레벨로 가기 때문에 0.1μs + 1μs를 하는 것 - T = H*
- T = (0.95)(0.1μs) + (0.05)(0.1μs + 1μs) = 0.095 + 0.055 = 0.15μs
- miss rate가 hit rate 대신 사용되는 이유
- HIT와 MISS의 큰 차이
- L1 및 메인 메모리만 있는 경우 100배 일 수 있다.
- 99% HIT가 97%의 두 배라고 하면 믿으시겠습니까?
- 고려 사항
- cache hit time of 1 cycle
- miss penalty of 100 cycles - Average Access Time
- 97% hits : 약 4 cycles
- 99% hits : 약 2 cycles
- 고려 사항
- 따라서 miss rate가 hit rate 대신 사용 되는 이유이다.
- HIT와 MISS의 큰 차이
- Average Access Time
- T = H * sT1 + (1 - H)(T1 + T2)
- T = - T2 H + (T1 + T2)
더보기
<시간 단위 정리>
ms : 10-3ss
μs : 10-6s
ns : 10-9ss
2. Cache Memory
1) Cache Memory
- Motivation(동기 부여)
- 명령어의 경우 프로세서는 명령어를 가져오기 위해 적어도 한 번은 메모리에 액세스하고, 종종 한 번 이상 추가로 액세스한다.
- 프로세서가 명령을 실행할 수 있는 속도는 memory cycle time에 의 해 분명히 제한된다.
- 프로세서 속도와 메모리 속도가 일치하지 않기 때문
- Solution(해결책)
- 프로세서와 메모리 사이에 작고 빠른 메모리, 즉 캐시를 제고앟여 locality의 원리를 사용
- 자주 액세스하는 메모리 block을 캐시에 보관
- Temporal locality
- Spatial locality
2) Cache Organzation
- 공간적 지역성과 시간적 지역성을 활용하기 위한 전략은?
- 공간적 지역성의 경우
- 더 큰 캐시 블록을 사용과 prefetching(사전 추출)함으로
- 대부분의 가까운 미래의 메모리 참조는 블록의 다른 바이트에 대한 것일 가능성이 높음
- 시간적 지역성의 경우
- 최근에 사용된 명령어와 데이터 값을 캐시 메모리에 저장함으로써
- 공간적 지역성의 경우

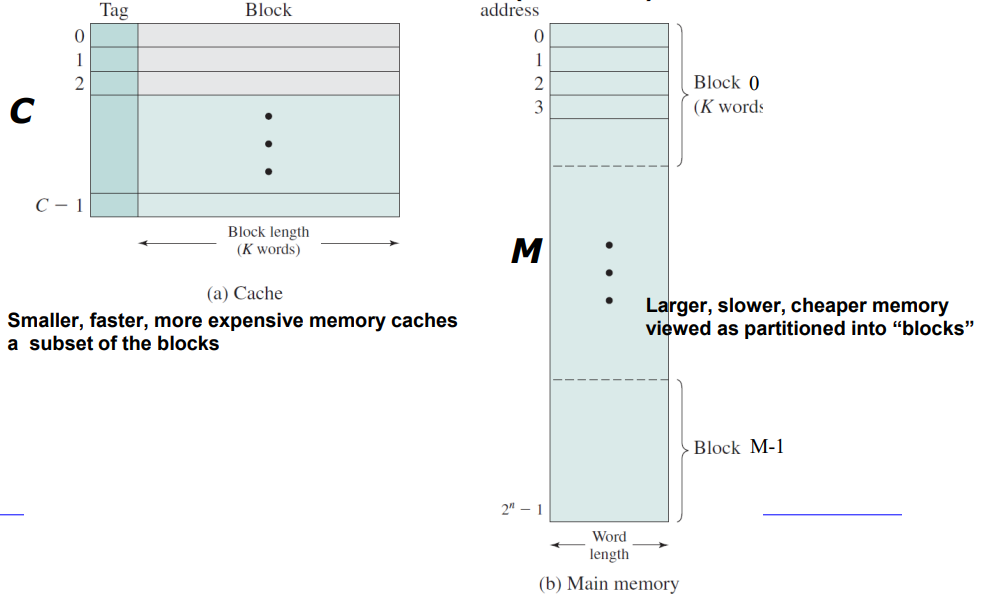
- 메인 메모리는 up to2n addressable word(주소 지정 가능한 최대 2n개의 단어)로 구성된다.
- fixed-length M 블록(=2n/K)가 있다
- 캐시는 각각 K 단어의 C slot으로 구성된다(C< M)
3) Cache Design
- 새로운 데이터 블록이 캐시에 읽힐 때
- Mapping function(매핑 함수)는 블록이 차지할 캐시 위치를 결정
- Tag는 현재 저장 중인 특정 블록을 식별

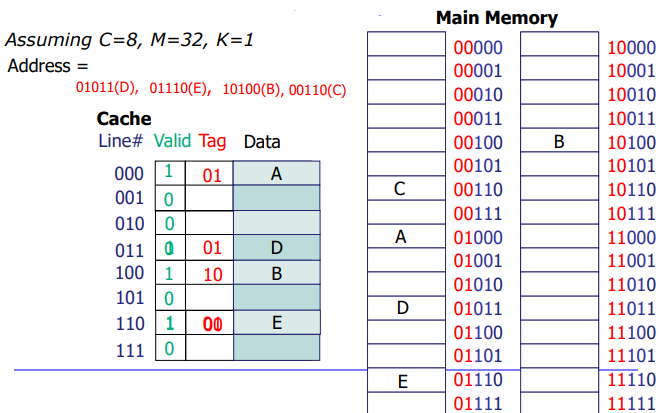
(1) Direct Mapped(One line per set)
- 각 메모리의 위치가 캐사 내에서 정확히 한 곳에만 매핑되는 구조
- 메인 메모리의 엔트리는 총 32개이므로 5비트로 다 표현이 가능하다
- 캐시 엔트리의 주소는 캐시 태그 비트를 포함하므로 3비틀르 각 캐시 엔트리를 구분하는데 사
(2) 2-Way Set-Associative(Two lines per set)
- 장점 : HIT 비율을 증가시킬 수 있음(무조건적이지는 않음)
- 단점 : 스캔 비용이 올라감(여러개의 라인을 확인해야하기 때문)

(3) Impact
- Impact of associativity(연관성의 영향)
- mapping 기능이 유연할수록 지정된 블록이 캐시에 있는지 확인하기 위해 검색하는 데 필요한 회로가 복잡해진다.
- 높은 연결성은 구현 비용이 많이 들고 신속하게 구현하기 어려움
- Impact of cache size
- 캐시가 클수록 hit rate가 증가하는 경향이 있음
- 반면에, 큰 기억을 더 빨리 실행시키기는 어려움
- 합리적으로 작은 캐시가 성능에 상당한 영향을 미칠 수 있음
- Impact of block size
- 블록 크기가 작은 크기에서 큰 크기로 증가하면 hit rate가 처음에는 증가
- 블록 크기를 늘린다고 해서 반드시 성능이 향상되는 것은 아님
4) Cache Read Operation
- 프로세서가 읽을 단어의 주소, RA를 생성할 때

5) Cache Write Operation
- What to do on a write-hit?
- Write-trough(메모리에 즉시 쓰기)
- 블록이 업데이트될 때마다 쓰기가 발생할 수 있다.
- Wirte-back(라인을 교체할 때마다 메모리에 쓰기 지연)
- dirty bit 필요(메모리와 다른 라인인지 여부)
- 메모리 쓰기 작업을 최소화하지만 main memory는 더 이상 사용되지 않는 상태(absolete state)로 둔다.
- 이는 다중 프로세서 작동 및 I/O 하드웨어 모듈에 의한 DMA(Direct Memory Access)를 방해할 수 있다.
- Write-trough(메모리에 즉시 쓰기)
- What to do on a read-hit?
- Write-allocate(캐시에 로드, 캐시에서 라인 업데이트)
- 이후에 해당 위치에 더 많은 쓰기가 발생하면 더 좋다.
- No-write-allocate(메모리에 직접 쓰기, 캐시에 로드되지 않음)
- Write-allocate(캐시에 로드, 캐시에서 라인 업데이트)
- Typical
- Write-back + Write-allocate
6) Example in Multi-Processors
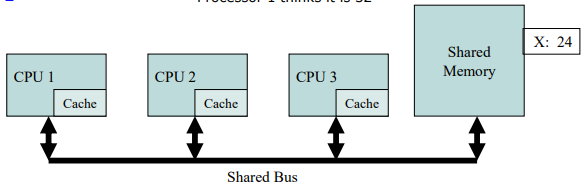
- Memory Coherence(메모리 일관성)의 문제
- 프로세서 1이 x를 읽음: 메모리에서 24를 가져와 캐시함
- 프로세서 2가 x를 읽음: 메모리에서 24를 가져와 캐시함
- 프로세서 1에서 x에 32 쓰기: 로컬로 캐시된 복사본이 업데이트 됨
- 프로세서 3이 x를 읽음: 어떤 값을 읽을까? - 24
- 메모리와 프로세서 2는 24라고 생각함
- 프로세서 1은 32라고 생각함
3. I/O Communcation Techniques
1) I/O Device Overview
- I/O 컨트롤러는 I/O 장치에 필요한 인터페이스를 제공한다..
- Interface : 시스템 소프트웨어가 작동을 제어할 수 있도록 함
- Internals : 기능 구현에 대한 책임
- 컨트롤러는 버스에 각각 컨트롤러의 레지스터에 해당하는 3개의 주소를 가진다.
- Status register : 장치의 현재 상태를 보려면 읽기
- Control register : 장치에서 특정 작업을 수행하도록 지시
- Data register : 장치에 데이터를 전달하거나 장치에서 데이터를 가져온다.
- 더 복잡한 장치에는 여러 개의 contorl과 status register가 있다.
2) I/O Address Space
- I/O 장치에는 다음의 목적으로 주소가 있다.
- Port-mapped I/O(I/O 지침)
- I/O 장치에는 별도의 주소 공간(I/O 전용)이 있다.
- I/O를 위한 주소 공간은 main memory를 위한 주소 공간과 분리됨
- 추가 I/O 명령은 버스 라인을 트리거하여 적절한 장치 및 제어를 선택한다.
- x86 아키텍쳐의 경우, 'in' 및 'out' 지침
- I/O 장치에는 별도의 주소 공간(I/O 전용)이 있다.
- Memory-mapped I/O
- Memory-mapped I/O는 동일한 주소 공간을 사용하여 메모리 및 I/O 장치를 모두 처리한다.
- I/O 주소를 일반 물리적 메모리에 사용할 수 없어야 함
- 일반 지침(load, store)에서 사용할 수 있다.
- Memory-mapped I/O는 동일한 주소 공간을 사용하여 메모리 및 I/O 장치를 모두 처리한다.
- 두 가지 방법 모두 사용할 수 있다.
- Port-mapped I/O(I/O 지침)
3) I/O Communication Techniques
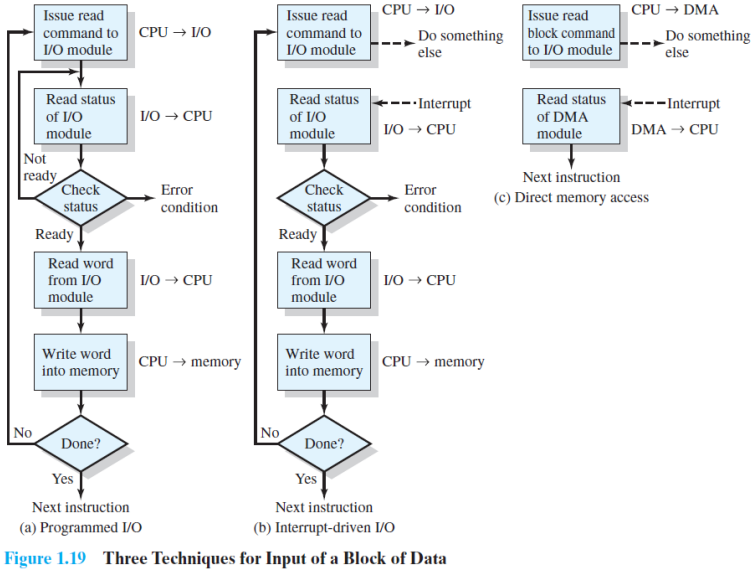
(1) Programmed I/O(= Polling I/O)
- HOST는 I/O 모듈에 읽기 명령을 보낸다.
- 컨트롤러가 명령 레지스터를 읽고 읽기 명령을 확인한다.
- 완료될 때까지 호스트가 상태 점검 루프에 반복적으로 있어야 함
- 장치로부터 I/O를 위한 Wait을 위해 busy-wait cycle이다.
- 장치가 빠른 경우 합리적임
- 장치 속도가 느리면 비효율적임
- 장치로부터 I/O를 위한 Wait을 위해 busy-wait cycle이다.
- I/O 모듈에서 호스트 읽기 및 메모리에 word 쓰기

<Polling I/O 정리>
1. 작동방식
1) CPU는 I/O 작업을 시작
2) I/O 작업이 완료될 때까지 CPU는 I/O 장치를 지속적으로 검사
3) I/O 작업이 완료되면 CPU는 결과를 처리
4. 작업이 완료되지 않으면 CPU는 계속해서 장치를 검사하고, 작업을 완료될 때까지 반복함
→ 단순한 구조와 구현이 용이
→ but, CPU의 자원을 지속적으로 사용하여 비효율적이고 CPU가 다른 작업을 할 수 없음
(2) Interrupt-Driven I/O
- CPU가 모듈에 I/O 명령을 실행한 다음 다른 유용한 작업을 수행하는 방법
- 그러면 I/O 모듈이 프로세서가 처리하는 것을 interrupt한다.
- 단순하게 Pragrammed I/O보다 효율적일 수 있음
- 여전히 대규모 데이터 이동을 위해 CPU의 적극적인 개입 필요(mode switch가 필요해서)
- I/O 모듈에서 메모리로 이동하는 모든 데이터 word는 프로세서를 통과해야 한다.
- interrupt를 하기 위해서는 interrupt handle에 접근해야 해서 커널 모드로 전환이 필요
→ 큰 데이터의 이동인 경우 mode switch 비용이 많아 질 수 있다.
- 그러면 I/O 모듈이 프로세서가 처리하는 것을 interrupt한다.

<Interrupt driven I/O 정리>
1. 작동방식
1) I/O 작업을 시작
2) I/O 장치는 작업이 완료되면 인터럽트를 발생
3) CPU는 인터럽트를 감지하고, 현재 수행 중인 작업을 중단하고 인터럽트 처리 루틴을 수행
4) 인터럽트 처리 루틴은 I/O 작업 결과를 처리하고, 필요한 경우 CPU에게 추가적인 작업을 지시
5) 인터럽트 처리가 완료되면 CPU는 이전 작업을 계속함
→ I/O 작업을 처리하는 동안 다른 작업이 가능해 CPU 자원을 효율적으로 사용할 수 있음
→ 계속해서 장치를 검사하지 않아도 됨
→ but, 인터럽트 처리 루틴이 수행되는 동안 CPU는 다른 작업을 할 수 없어 대용량일 경우 비용 증가
(3) DMA(Direct Memory Access)
- 대용량 데이터의 경우보다 효율적인 기술이 필요
- CPU를 bypass(우회)하여 I/O 장치와 메모리 간에 직접 데이터 전송
- DMA 전송의 단계
- 명령 블록을 DMA에 발급
- Source 와 destination의 주소, R/W 모드, 바이트 수
- 전송이 완료되면 DMA 모듈이 signal completion으로 인터럽트를 전송
- 명령 블록을 DMA에 발급
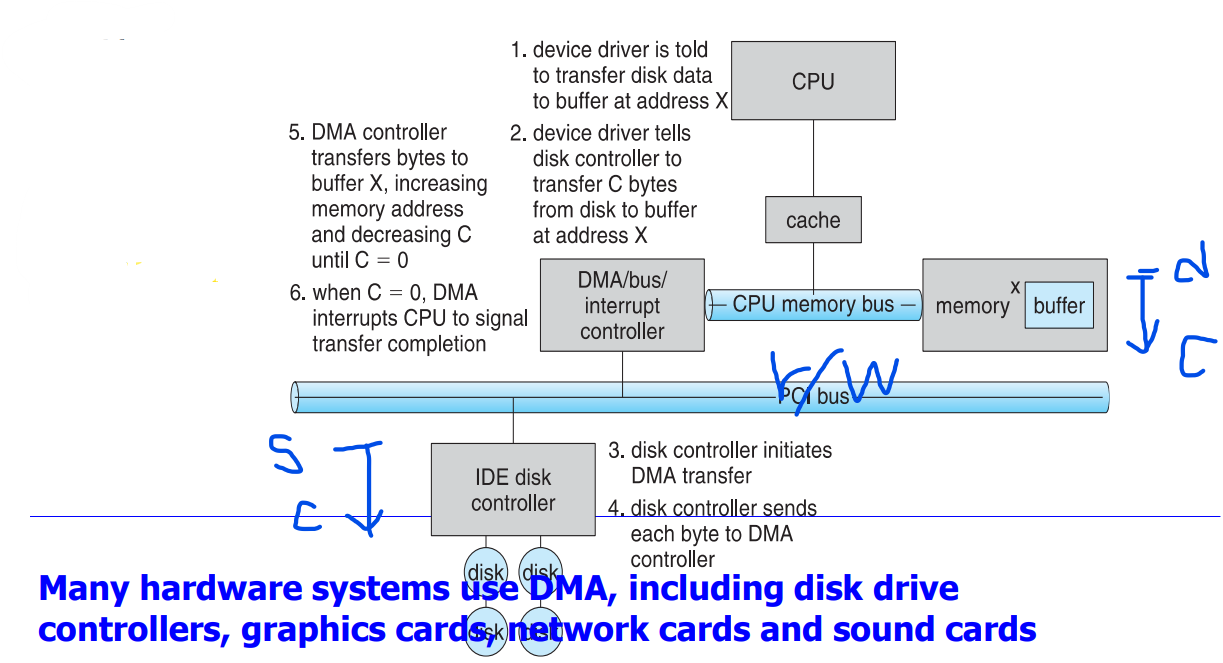
- 시스템 버스에 별도의 컨트롤러가 있거나 I/O 컨트롤러에 통합될 수 있다.
<DMA 정리>
1. 작동 방식
1) CPU는 DMA 컨트롤러를 통해 입출력 장치와 메모리 간 데이터 전송을 위한 DMA 요청을 보냄
2) DMA 컨트롤러는 시스템 버스를 통해 CPU와 입출력 장치, 메모리 간 데이터 전송을 수행
3) 데이터 전송이 완료되면, DMA 컨트롤러는 인터럽트를 발생시켜 CPU에게 전송 완료를 알림
→ CPU가 입출력 작업에 관여하지 않아도 되므로, CPU가 다른 작업을 수행할 수 있으며, 시스템 전체의 처리량이 향상
→ 입출력 장치와 메모리 간 데이터 전송 속도가 시스템 버스를 통한 전송보다 더욱 빠르기 때문에, 입출력 작업의 처리 시간이 단축
→ but, 메모리에 올바른 데이터가 저장되었는지 확인하기 위한 추가적인 작업이 필요
(4) Three techniques
- Programmed I/O(Polling)
- 프로세스는 I/O 작업이 완료될 때까지 주기적으로 I/O 모듈의 상태를 점검한다.
- Interrupt-driven I/O
- I/O 모듈이 완료되면 프로세서가 중단된다.
- DMA(Direct Memory Access)
- 장치 컨트롤러는 CPU 개입 없이 buffer storage에서 메인 메모리로 데이터 블록을 직접 전송한다
4) Symmetric Multiprocessors(SMP)
(1) Multiprocessor
- 하나의 프로세서 : Uniprocessor
- 다중 프로세서의 장점 : 단위 시간당 처리할 수 있는 일의 양이 늘어남
- SMP(대칭적 다중 처리기) vs ASMP(비댕칭적 다중처리기)
(2) Symmetric Multiprocessor
- SMP는 다음과 같은 특성을 가진 stand-alone(독립 실행형) computer system으로 정의할 수 있다.
- 두 개 이상의 유사한 comparable capability의 프로세서가 있다.
- 이러한 프로세서는 동일한 메인 메모리 및 I/O 기능을 공유하며 버스를 통해 상호 연결된다.
- 모든 프로세서가 I/O 장치에 대한 액세스를 공유
- 모든 프로세서가 동일한 기능을 수행할 수 있다.

(3) Advanced PIC (APIC) for SMP
- Advanced PIC(APIC) for SMP systems
- APIC은 CPU를 선택한다.
- 해당 로컬 APIC에 신호를 전달
- Local APIC(LAPIC)
- SMP의 각 CPU당 1개
PIC(Programmable Interrupt Controller) : 컴퓨터 시스템에서 인터럽트를 관리하는 장치
(4) Heterogeneous Architectures
- Heterogeneous Architectures
- 다양한 타입의 CPU 및 GPU(ex. big-little)
- AI 애플리케이션을 처리하기 위한 새로운 AI 프로세서
- 새로운 아키텍처에는 새로운 알고리즘이 필요
- Multi-layter Software Stack
- 특정 서비스를 제공하거나 다양한 애플리케이션 통합
- 계층 간 상호 작용 및 multi-layer workloads
- ex. android, EdgeX, OSGi, Hadoop ...
- Heterogeneous Applications and QoS
- 고품질 보증 유지(Maintain a quality guarantee
- 공정한 활용이 더욱 어려움(Fair utilization is mroe challenging)
- ex . IoT + AI
5) Summary
- Basis Elements - evolution of the Microprocessor
- Processor
- 프로세서 레지스터
- 명령 실행
- Interrupt
- 인터럽트 메커니즘
- Progammable Interrupt Controller
- Interrupt vs Exception
- Multiple Interrupts
- Memory Hierarchy
- Temporal/Spatial Locality
- Average Access Time
- Cache Memory
- Cache Overview, Cache Organization, Cache Design, Cache Read/Write
- I/O Communication Techniques
- I/O Device and Controller
- MMIO vs PMIO
- Polling I/O, Interrupt-driven I/O, DMA
- Multi-processors
- Heterogeneous Architectures
'오퍼레이팅 시스템' 카테고리의 다른 글
| 오퍼레이팅 시스템 : Process Description and Control Ⅱ (0) | 2023.04.08 |
|---|---|
| 오퍼레이팅 시스템 : Proccess Description and Control Ⅰ (0) | 2023.04.07 |
| 오퍼레이팅 시스템 : Operating System Overview (0) | 2023.03.31 |
| 오퍼레이팅 시스템 : Computer System Overview Ⅰ (7) | 2023.03.19 |
| 오퍼레이팅 시스템 : OS (0) | 2023.03.19 |


