1. Accessing SQL From a Programming Language
1) Accessing SQL from a Programming Language
- DB 프로그래머가 범용 프로그래밍 언어(general-purpose programming language)에 접근해야 하는 이유
- SQL은 범용 언어의 완전한 표현력을 제공하지 않기 때문에 모든 쿼리를 SQL로 표현할 수는 없다.
- 보고서 인쇄, 사용자와의 상호 작용 또는 쿼리 결과를 그래픽 사용자 인터페이스로 보내는 등 선언적이지 않은 작업은 SQL 내에서 수행할 수 없다.
- General-purpose program : 함수 모음을 사용하여 데이터베이스 서버에 연결하고 데이터베이스 서버와 통신할 수 있음
- Embedded SQL : 프로그램이 데이터베이스 서버와 상호작용할 수 있는 수단을 제공
- SQL 문은 컴파일 시 함수 호출로 변환됨
- 런타임에 이러한 함수 호출은 동적 SQL 기능을 제공하는 API를 사용하여 데이터베이스에 연결됨
2) JDBC
(1) JDBC란
- JDBC : SQL을 지원하는 데이터베이스 시스템과 통신하기 위한 Java API
- 데이터를 쿼리 및 업데이트하고 쿼리 결과를 검색하기 위한 다양한 기능 제공
- 데이터베이스에 존재하는 relation 및 relation의 속성이름과 유형에 대한 쿼리와 같은 메타데이터 검색을 지원
- 데이터베이스와 통신하기 위한 모델
- Open a connection
- Create a "statement" obejct → 쿼리를 만드는 객체
- statement obejct를 사용하여 쿼리를 실행하여 쿼리를 보내고 결과를 가져온다.
- 오류를 처리하는 Exception mechanism
(2) JDBC 코드 예시
<JDBC 코드>
- Java 7 alc JDBC 4 이상에서 작동
- "try ( ... )" 구문 ("try with resources")로 열린 Resource(자원)들은 try block의 끝에서 자동으로 close(종료)된다.
public static void JDBCexample(String dbid, String userid, String passwd)
{
try (Connection conn = DriverManager.getConnection(
"jdbc:oracle:thin:@db.yale.edu:2000:univdb", userid, passwd);
Statement stmt = conn.createStatement();
)
{
… Do Actual Work ….
}
catch (SQLException sqle) {
System.out.println("SQLException : " + sqle);
}
}<Old version JDBC 코드>
- JDBC 4 이상에서는 Class.forName이 필요하지 않음
public static void JDBCexample(String dbid, String userid, String passwd)
{
try {
Class.forName ("oracle.jdbc.driver.OracleDriver"); // 최신 버전과 다른 부분
Connection conn = DriverManager.getConnection(
"jdbc:oracle:thin:@db.yale.edu:2000:univdb", userid, passwd);
Statement stmt = conn.createStatement();
… Do Actual Work ….
stmt.close();
conn.close();
}
catch (SQLException sqle) {
System.out.println("SQLException : " + sqle);
}
}<Update to database>
try {
stmt.executeUpdate(
"insert into instructor values('77987', 'Kim', 'Physics', 98000)");
} catch (SQLException sqle)
{
System.out.println("Could not insert tuple. " + sqle);
}<Execute query and fetch and print results>
ResultSet rset = stmt.executeQuery(
"select dept_name, avg (salary)
from instructor
group by dept_name");
while (rset.next()) {
System.out.println(rset.getString("dept_name") + " " + //쿼리 결과를 출력하는 부분
rset.getFloat(2));
}1. 결과 필드 가져오기
- 만약 dept_name이 select 결과의 첫번째 인자라면
rset.getString("dept_name") = rset.getString(1)
2. Null 값 처리
- int a = rset.getInt("a");
if(rset.wasNull()) Systems.out.println("Got null value");
(3) JDBC SUBSECTIONS
- 데이터베이스와 연결
- SQL문을 데이터베이스 시스템으로 전송
- 예외 및 리소스 관리
- 쿼리 결과 검색
- 준비된 구문
- 호출 가능한 구문
- 메타데이터 기능
- 기타 기능
- Python에서 데이터베이스 접근
(4) Prepared Statement
- Warning : 사용자로부터 입력을 받아 쿼리에 추가할 때 항상 Prepared Statement 사용
- 문자열을 연결하여 쿼리를 만들지 않음
-
insert into instructor values(' " + ID + " ', ' " + name + " ', ' " + dept_name + " ', " + balance + ")
- 위의 경우 "D'Souze"라는 이름은 어떻게 될까? → 에러가 발생할 수 있다
PreparedStatement pStmt = conn.prepareStatement("insert into instructor values(?,?,?,?)");
pStmt.setString(1, "88877");
pStmt.setString(2, "Perry");
pStmt.setString(3, "Finance");
pStmt.setInt(4, 125000);
pStmt.executeUpdate();
pStmt.setString(1, "88878");
pStmt.executeUpdate();(5) SQL Injection
- 쿼리가 다음을 사용하여 구성된다고 가정
- select * from instructor where name = ' " + name + " '
- 사용자가 이름을 입력하는 대신 다음을 입력한다고 가정
- X' or 'Y' = 'Y
- 그러면 결과 구문이 다음과 같다.
- select * form instructor where name = '" + "x' or 'Y' = 'Y" + "'
- 즉, 다음과 같음
- select * from instructor where name = 'X' or 'Y' = 'Y'
- 사용자는 심지어 사용할 수 있다.
- X'; update instructor set salary = salary + 10000;
- 준비된 구문은 내부적으로 다음을 사용: select * from instructor where name = 'X\' or \'Y\' = \'Y'
- 항상 사용자 입력을 매개 변수로 사용하여 준비된 구문 사용
(6) Metadata Features
ResultSet metadata
// 예시 : 쿼리를 실행하여 ResultSets rs를 가져온 후
ResultSetMetaData rsmd = rs.getMetaData(); // 속성에 관한 정보를 가져옴
for(int i=1;i<=rsmd.getColumnCount();i++) {
System.out.println(rsmd.getColumnName(i));
System.out.println(rsmd.getColumnTypeName(i));Database metadata
DatabaseMetaData dbmd = conn.getMetaData();
// Arguments to getColumns: Catalog, Schema-pattern, Table-pattern, and Column-Pattern
// Returns: One row for each column; row has a number of attributes such as COLUMN_NAME, TYPE_NAME
// The value null indicates all Catalogs/Schemas.
// The value “” indicates current catalog/schema
// The value “%” has the same meaning as SQL like clause
ResultSet rs = dbmd.getColumns(null, "univdb", "department", "%");
while( rs.next()) {
System.out.println(rs.getString("COLUMN_NAME"),
rs.getString("TYPE_NAME");
}
// Arguments to getTables: Catalog, Schema-pattern, Table-pattern, and Table-Type
// Returns: One row for each table; row has a number of attributes such as TABLE_NAME, TABLE_CAT, TABLE_TYPE, ..
// The value null indicates all Catalogs/Schemas.
// The value “” indicates current catalog/schema
// The value “%” has the same meaning as SQL like clause
// The last attribute is an array of types of tables to return.
// TABLE means only regular tables
ResultSet rs = dbmd.getTables (“”, "", “%", new String[] {“TABLES”});
while( rs.next()) {
System.out.println(rs.getString(“TABLE_NAME“));
}(7) Finding Primary key
DatabaseMetaData dmd = connection.getMetaData();
// Arguments below are: Catalog, Schema, and Table
// The value “” for Catalog/Schema indicates current catalog/schema
// The value null indicates all catalogs/schemas
ResultSet rs = dmd.getPrimaryKeys(“”, “”, tableName);
while(rs.next()){
// KEY_SEQ는 기본 키에서 속성의 위치를 나타낸다. 이는 기본 키에 여러 속성이 있는 경우 필요
System.out.println(rs.getString(“KEY_SEQ”),
rs.getString("COLUMN_NAME");
}(8) Transaction Control in JDBC
- 기본적으로 각 SQL 문은 자동으로 커밋되는 별도의 트랜잭션으로 처리됨
- 여러 업데이트가 있는 트랜잭션에 대한 잘못된 생각
- 연결에서 자동 커밋을 해제할 수 있다.
- conn.setAutoCommit(false);
- 그런 다음 트랜잭션을 명시적으로 커밋하거나 롤백(마지막 커밋 이후 다 사라짐)해야 한다.
- conn.commit(); 또는 conn.rollback();
- conn.setAutoCommit(true)는 자동 커밋을 켠다.
(9) Other JDBC Features
- 함수 및 프로시저 호출
-
CallableStatement cStmt1 = conn.prepareCall("{? = call some function(?)}"); → 함수 호출
-
CallableStatement cStmt2 = conn.prepareCall("{call some procedure(?,?)}"); → 함수 호출
-
- 큰 객체 타입 처리
- getString() 방법과 유사하지만 각각 Blob과 Clob 유형의 객체를 반환하는 getBlob() 및 getClob()
- getByte()를 통해 이러한 객체에서 데이터를 가져옴
- open stream을 java Blob 또는 Clob 객체와 연결하여 큰 객체 업데이트
- blob.setBlob(int parameterIndex, InputStream inputStream);
(10) JDBC Resources
- JDBC Basics Tutorial :https://docs.oracle.com/javase/tutorial/jdbc/index.html
(11) SQLJ
- JDBC는 지나치게 동적이므로 컴파일러가 오류를 감지할 수 없다.
- SQLJ : Java에 포함된 SQL
#sql iterator deptInfoIter ( String dept_name, int avgSal);
deptInfoIter iter = null;
#sql iter = { select dept_name, avg(salary) from instructor
group by dept_name };
while (iter.next()) {
String deptName = iter.dept_name();
int avgSal = iter.avgSal();
System.out.println(deptName + " " + avgSal);
}
iter.close();
3) ODBC
(1) ODBC
- Open DataBase connectivity(ODBC) 표준
- 응용 프로그램이 데이터베이스 서버와 통신하기 위한 표준이다.
- Aplication Program Interface(API)
- 데이터베이스와의 연결을 open한다.
- 쿼리 및 업데이트 전송
- result를 다시 가져오기
- GUI, 스프레드시트 등과 같은 응용 프로그램에서 ODBC를 사용할 수 있다.
(2) Embedded SQL
- SQL 표준은 C, C++, Java, Fortran 및 PL/1과 같은 다양한 프로그래밍 언어로 SQL의 embedding을 정의한다.
- SQL 쿼리가 포함된 언어를 host language라고 하며, 호스트 언어에서 허용되는 SQL 구조는 Embedded SQL로 구성됨
- 이러한 언어의 기본 형식은 SQL을 PL/1에 포함하는 R 시스템의 형식을 따름
- EXEC SQL 문은 호스트 언어에서 preprocessor에 포함된 SQL 요청을 식별하는데 사용된다.
- EXEC SQL <embedded SQL statement>;
참고 : 언어에 따라 다름
COBOL 같은 일부 언어에서는 세미콜론(;)이 END_EXEC로 대체됨
Java Embedding에서는 #SQL { ... } 를사용
- SQL문을 실행하기 전에 먼저 프로그램을 데이터베이스에 연결해야 함.
EXEC-SQL connect to server user user-name using password;
// 여기서 서버는 연결이 설정될 서버를 식별함(3) Host language 변수
- Host language의 변수는 포함된 SQL 문 내에서 사용할 수 있음. SQL 변수(Ex. credit_mount)와 구별하기 위해 콜론(:)을 선행함
→ :credit_ammount - 위와 같이 사용된 변수는 아래 그림과 같이 DECLARE 섹션 내에 선언되어야 한다. 그러나 변수를 선언하는 구문은 일반적이 Host language 구문을 따름
EXEC-SQL BEGIN DECLARE SECTION
int credit-amount ;
EXEC-SQL END DECLARE SECTION;(4) Cursor c
- 내장된 SQL 쿼리를 작성하려면 다음을 사용함 → 변수 c는 쿼리를 식별하는 데 사용됨
- declare c cursor for <SQL query>
- 예시
- 호스트 언어 내에서 호스트 언어의 credit_mount 변수에 저장된 학점 수보다 더 많은 학점을 이수한 학생의 ID와 이름을 찾는다.
- SQL에서 쿼리를 다음과 같이 지정
EXEC SQL
declare c cursor for
select ID, name
from student
where tot_cred > :credit_amount # tot_cred : SQL 변수 / credit_amount : 호스트 언어 변수
END_EXEC(5) open, fetch 구문
- open 구문은 다음과 같다.
- 이 구문을 사용하면 데이터베이스 시스템이 쿼리를 실행하고 결과를 temporary relation 내에 저장
- 쿼리는 open 구문이 실행될 때 호스트 언어 변수 credit_amount의 값을 사용
EXEC SQL open c;- fetch 구문을 사용하면 쿼리 결과에서 하나의 튜플 값이 호스트 언어 변수에 배치된다.
- 쿼리 결과에서 연속적인 튜플을 가져오는 경우 fetch 구문을 반복해서 호출
EXEC SQL fetch c into :si, :sn END_EXEC #변수 si, sn에 c가 가리키는 튜플 각 속성에 대한 값 할당(6) close구문
- SQL 통신 영역(SQLCA)에서 SQLSTATE 변수가 '02000'으로 설정되어 더이상 데이터를 사용할 수 없음을 나타냄
- close구문을 사용하면 데이터베이스 시스템이 쿼리 결과를 유지하는 temporary relation을 삭제
EXEC SQL close c;참고 : 위의 세부 정보는 언어에 따라 다름
→ 예를 들어, Java 임베딩은 결과 튜플을 단계적으로 수행하도록 Java iterator를 정의
(7) Updates Through Embedded SQL
- 데이터베이스 수정(업데이터, 삽입 및 삭제)을 위한 포함된 SQL 식
- cursor가 업데이트용임을 선언하여 cursor로 가져온 튜플을 업데이트할 수 있다.
EXEC SQL
declare c cursor for
select *
from instructor
where dept_name = 'Music'
for update- 그건 다음 cursor에서 fetch 작업을 수행하여(앞에서 설명한 대로) 튜플을 반복하고 각 튜플을 가져온 후 다음 코드를 실행한다.
update instructor
set salary = salary + 1000
where current of c
2. Functions and Procedures
1) Functions and Procedures
- 함수와 프로시저를 통해 "business logic"을 데이터베이스에 저장하고 SQL 문에서 실행할 수 있다.
- 이는 SQL의 절차 구성 요소 또는 Java, C 또는 C++와 같은 외부 프로그래밍 언어로 정의할 수 있다.
- 여기서 제시하는 구문은 SQL 표준에 의해 정의된다.
- 대부분의 데이터베이스는 이 구문의 nonstandard version을 구현함
2) Function
(1) 함수 선언
- department 이름이 주어지면 해당 department의 강사 수를 반환하는 함수 정의
create function dept_count (dept_name varchar(20))
returns integer
begin
declare d_count integer;
select count (* ) into d_count
from instructor
where instructor.dept_name = dept_name
return d_count;
end- dept_count 함수를 사용하면 강사가 12명 이상인 모든 학과의 학과 이름과 예산을 찾을 수 있다.
select dept_name, budget
from department
where dept_count(dept_name) > 12(2) Table Functions
- SQL 표준은 테이블을 결과로 반환할 수 있는 함수를 지원함. 이러한 함수를 table function이라고 함
- 예시 : Return all instructors in a given department
create function instructor_of (dept_name char(20))
returns table (
ID varchar(5),
name varchar(20),
dept_name varchar(20),
salary numeric(8,2))
return table
(select ID, name, dept_name, salary
from instructor
where instructor.dept_name = instructor_of.dept_name)
#instructor_of를 제외해도 함수 매개 변수로 인식- table fuction 사용
select *
from table(instructor_of('Music'))3) Procedures
(1) SQL Procedures
- dept_count 함수를 프로시저로 써서 구현
- 키워드 in 및 out는 할당된 값이 있을 것으로 예상되는 파라미터와 결과를 반환하기 위해 프로시저에서 값이 설정된 파라미터이다.
- 프로시저는 SQL 프로시저 또는 Embedded SQL에서 call 구문을 사용하여 호출할 수 있다.
create procedure dept_count_proc (in dept_name varchar(20),
out d_count integer)
begin
select count(*) into d_count
from instructor
where instructor.dept_name = dept_count_proc.dept_name
end
# Usage
select *
declare d_count integer;
call dept_count-proc('Physics', d_count);- 프로시저 및 함수는 dynamic SQL에서도 호출할 수있다.
- SQL은 동일한 이름이지만 인수 수가 다른 프로시저들을 허용한다.
- 이름과 인수 수는 프로시저를 식별하는데 사용
4) Language Constructs
(1) Language Constructs for Procedures & Functions
- SQL은 범용 프로그래밍 언어의 거의 모든 기능을 제공하는 구성을 지원
- Warning : 대부분의 데이터베이스 시스템은 아래 표준 구문의 자체 변형을 구현
- Compound statement(복합 구문): begin ... end
- begin과 end 사이에는 여러 SQL 문을 포함할 수 있다.
- 지역 변수는 복합 구문 내에서 선언할 수 잇다.
- while 및 repeat 구문
while boolean expression do
sequence of statements;
end while
# do-whlie과 유사
repeat
sequence of statements;
until boolean expression
end repeat- For loop
- 쿼리의 모든 결과에 대해 반복(iteration) 허용
# Find the budget all results of a query
declare n integer default 0;
for r as
select budget from department
do
set n = n + r.budget
end for- Conditional statement ( if-then-else)
if boolean expression
then statement or compound statement
elseif boolean expression
then statement or compound statement
else statement or compound statement
end if(2) Example procedure
- 강의실 정원을 초과하지 않도록 한 후 학생 등록
- 성공하면 0을 반환, 용량이 초과하면 -1을 반환
- 자세한 내용은 교재(p203)
- signaling of exception condition 및 declaring handlers for exceptions
declare out_of_classroom_seats condition
declare exit handler for out_of_classroom_seats
begin
...
end- begin 과 end 사이의 구문은 "signal out_of_classroom_seats"를 실행하여 예외를 발생 시킬 수 있다.
- handler는 조건이 발생하면 begin end 구문을 종료하는 작업을 수행해야 함
5) External Language Routines
- SQL을 사용하면 Java, C#, C 또는 C++와 같은 프로그래밍 언어로 함수를 정의할 수 있다.
- SQL에 정의된 함수보다 효율적일 수 있으며 SQL에서 수행할 수 없는 계산은 이러한 함수로 실행 가능
- 외부 언어 함수 및 프로시저 선언
create procedure dept_count_proc(in dept_name varchar(20), out count integer)
language C
external name '/usr/avi/bin/dept_count_proc'
create function dept_count(dept_name varchar(20))
returns integer
language C
external name '/usr/avi/bin/dept_count'- 외부 언어 함수/프로시저의 장점
- 더 효율적이고 더 표현력이 풍부한 작업을 수행할 수 있음
- 단점
- 함수를 구현할 코드는 데이터베이스 시스템에 로드되고 데이터베이스 시스템의 주소 공간에서 실행되어야 할 수 있음
- 데이터베이스 구조가 우발적으로 손상될 위험
- 보안 위험, 사용자가 무단 데이터에 접근할 수 있도록 허용할 수 있음
- 잠재적으로 성능이 저하되는 대신우수한 보안을 제공하는 대안이 있다.
- 데이터베이스 시스템 공간에서 직접 실행은 보안보다 효율성이 더 중요할 때 사용
- 함수를 구현할 코드는 데이터베이스 시스템에 로드되고 데이터베이스 시스템의 주소 공간에서 실행되어야 할 수 있음
(1) External Langauge Routins에 대한 Security
- 보안 문제를 해결하기 위해 다음 중 하나를 수행할 수 있다,
- sandbox 기술을 사용
- 즉, 데이터베이스 코드의 다른 부분에 접근하거나 손상시키는 데 사용할 수 없은 Java와 같은 안전한 언어를 사용
- 데이터베이스 프로세스의 메모리에 접근하지 않고 별도의 프로세스에서 외부 언어 함수/프로시저를 실행
- 프로세스 간 통신을 통해 전달되는 파라미터와 result
- sandbox 기술을 사용
- 둘 다 perfomance overhead가 있음
- 많은 데이터베이스 시스템은 데이터베이스 시스템 주소 공간에서 직접 실행할 뿐만 아니라 위의 접근 방식을 모두 지원
3. Triggers
1) Trigger란
- Trigger는 데이터베이스 수정의 부작용으로 시스템에서 자동으로 실행되는 구문이다.
- 트리거 메커니즘을 설계하려면 다음을 수행
- 트러기를 실행할 조건을 지정
- 트리거가 실행될 때 수행할 작업을 지정
- 트리거는 SQL:1999에서 SQL 표준에 도입되었지만 대부분의 데이터베이스에서 non-standard syntax를 사용하여 훨씬 이전에 지원되었음
- 여기에 설명된 구문은 데이터베이터 시스템에서 정확하게 작동하지 않을 수 있음 → 시스템 설명서 확인
2) Triggering Events and Actions in SQL
- Triggering event는 insert, delete 또는 update할 수 있다.
- 업데이트 시 트리거를 특정 속성으로 제한할 수 있음
- 예를 들어, after update of takes on grade
- 업데이트 전후의 속성 값을 참조할 수 있다.
- referencing old row as : 삭제 및 업데이트에 대해
- referencing new row as : 삽입 및 업데이트에 대해
- 트리거는 이번트 전에 활성화 될 수 있으며, 이는 추가 제약 조건을 사용하여야 함
→ 예를 들어, convert blank grades to null
create trigger setnull_trigger before update of takes
referencing new row as nrow
for each row
when(nrow.grade = '')
begin atmoic
set nrow.grade = null;
end;3) Trigger to Maintain credits_earned value
create trigger credits_earned after update of takes on (grade)
referencing new row as nrow
referencing old row as orow
for each row
when nrow.grade <> 'F' and nrow.grade is not null
and (orow.grade = 'F' or orow.grade is null)
begin atomic
update student
set tot_cred= tot_cred +
(select credits
from course
where course.course_id= nrow.course_id)
where student.id = nrow.id;
end;4) Statement Level Triggers
- 영향을 받는 각 행에 대해 별도의 작업을 실행하는 대신 트랜잭션의 영향을 받는 모든 행에 대해 단일 작업을 수행할 수 있다.
- for each row 대신에 for each statement 사용
- referencing old table 또는 referencing new table을 사용하여 영향을 받는 행을 포함하는 임시 테이블(transition tables이라고 불림)을 참조
- 다수의 행을 업데이트하는 SQL문을 처리할 때보다 효율적으로 처리할 수 있음
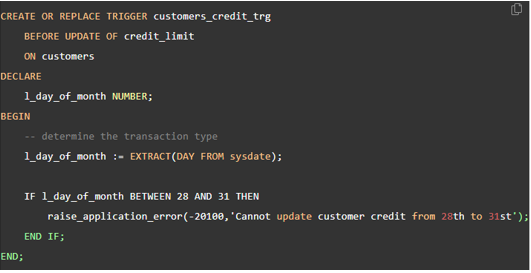
5) When Not to User Triggers
<트리거 사용하는 경우>
- 트리거는 이전에 다음과 같은 작업에 사용
- 요약 데이터 유지(ex. 각 학과에 대한 전체 월급)
- 특수 relation(change 또는 delta relation이라 불림)에 대한 변경사항을 기록하고 변경사항을 복제본에 적용하는 별도의 프로세스를 사용하여 데이터베이스 Replicate(복제)
- 이제 더 나은 방법이 있음
- 오늘날 데이터베이스는 요약 데이터를 유지 관리할 수 있는 Materialized view 기능을 제공
- 데이터베이스는 복제에 대한 built-in support(기본 제공 지원 기능)을 제공
- 대부분의 경우 트리거 대신 Encapsulation(캡슐화) 기능을 사용할 수 있다.
- 필드 업데이트 방법 정의
- 트리거를 사용하는 대신 업데이트 방법의 일부로 작업 수행
<트리거 사용이 위험한 경우>
- 예기치 않은 트리거 실행의 위험
- 백업 복사본에서 데이터 로드
- 원격 사이트에서 업데이트 복제
- 이러한 작업을 수행하기 전에 트리거 실행을 비활성화할 수 있다.
- 트리거 관련 기타 위험
- 트리거를 시작하는 중요 트랜잭션의 실패로 이어지는 오류
- Cascading execution
4. Recursive(재귀) Queries
1) SQL에서 Recursive
- SQL:1999는 recursive view 정의를 허용
- 예 : 특정 강의에 대해 직접 또는 간접적으로 어떤 강의가 선수강인지 찾아라
with recursive rec_prereq(course_id, prereq_id) as (
select course_id, prereq_id
from prereq
union
select rec_prereq.course_id, prereq.prereq_id,
from rec_rereq, prereq
where rec_prereq.prereq_id = prereq.course_id
)
select ∗
from rec_prereq위의 예제 view인 rec_prereq는 prereq relation의 transitive closure라고 불린다.
2) Power of Recursion
- Recursive view를 사용하면 transitive closure query와 같은 쿼리를 작성할 수 있으며, 이 쿼리는 recursion 또는 iteration 없이 작성할 수 없다.
- Intuition(직관) : 재귀 없이, 비재귀적 비반복적 프로그램은 prereq와 그 자체에 대한 고정된 join 횟수를 수행할 수 있다.
- 이는 고정된 수의 prerequisites만 제공할 수 있다.
- 고정된 비재귀적 쿼리가 주어지면 쿼리가 작동하지 않는 더 많은 수준의 prerequisites으로 데이터베이스를 구성할 수 있다.
- 대안 : 프로시저를 작성하여 필요한 횟수만큼 반복한다.
- findAllPrereqs 프로시저를 참조하기(책에서)
- Intuition(직관) : 재귀 없이, 비재귀적 비반복적 프로그램은 prereq와 그 자체에 대한 고정된 join 횟수를 수행할 수 있다.
- rec_prereq에 연속적인 튜플을 추가하는 반복을 사용하여 transitive closure을 계산
- 반복 프로세스의 각 단계는 rec_prereq의 재귀적 정의로부터 확장 버전을 생성
- 최종 결과를 recursive view의 fixed point라고 함
- recursive view는 단조로워야(monotonic) 함. 즉, preq에 튜플을 추가하면 rec_prereq에는 이전에 포함된 튜플이 모두 포함되어 있을 수 있다.

'데이터베이스' 카테고리의 다른 글
| 데이터베이스 : 6장 Database Design Using the E-R Model (0) | 2023.05.28 |
|---|---|
| 데이터베이스 : 5장 Advanced SQL(2) (0) | 2023.05.28 |
| Database 4장 : Intermediate SQL (0) | 2023.04.06 |
| Database 3장 : Introduction to SQL (0) | 2023.04.01 |
| Database 2장 : Intro to Relational Model (0) | 2023.03.19 |



